Published by TringTring.AI Team | Technical Analysis | 10 minute read
In the world of AI voice agents, milliseconds matter. The difference between a 300ms and 800ms response time can mean the difference between a natural, engaging conversation and a frustrating, robotic interaction that drives customers away. But why exactly does latency matter so much in conversational AI, and what does it take to achieve the coveted sub-500ms response time?
This comprehensive technical analysis explores the critical importance of latency in AI voice agents, breaks down the components that contribute to response delays, and provides actionable strategies for optimization. Whether you’re building voice AI systems or evaluating solutions for your enterprise, understanding latency is crucial for success.
What is Latency in AI Voice Agents?
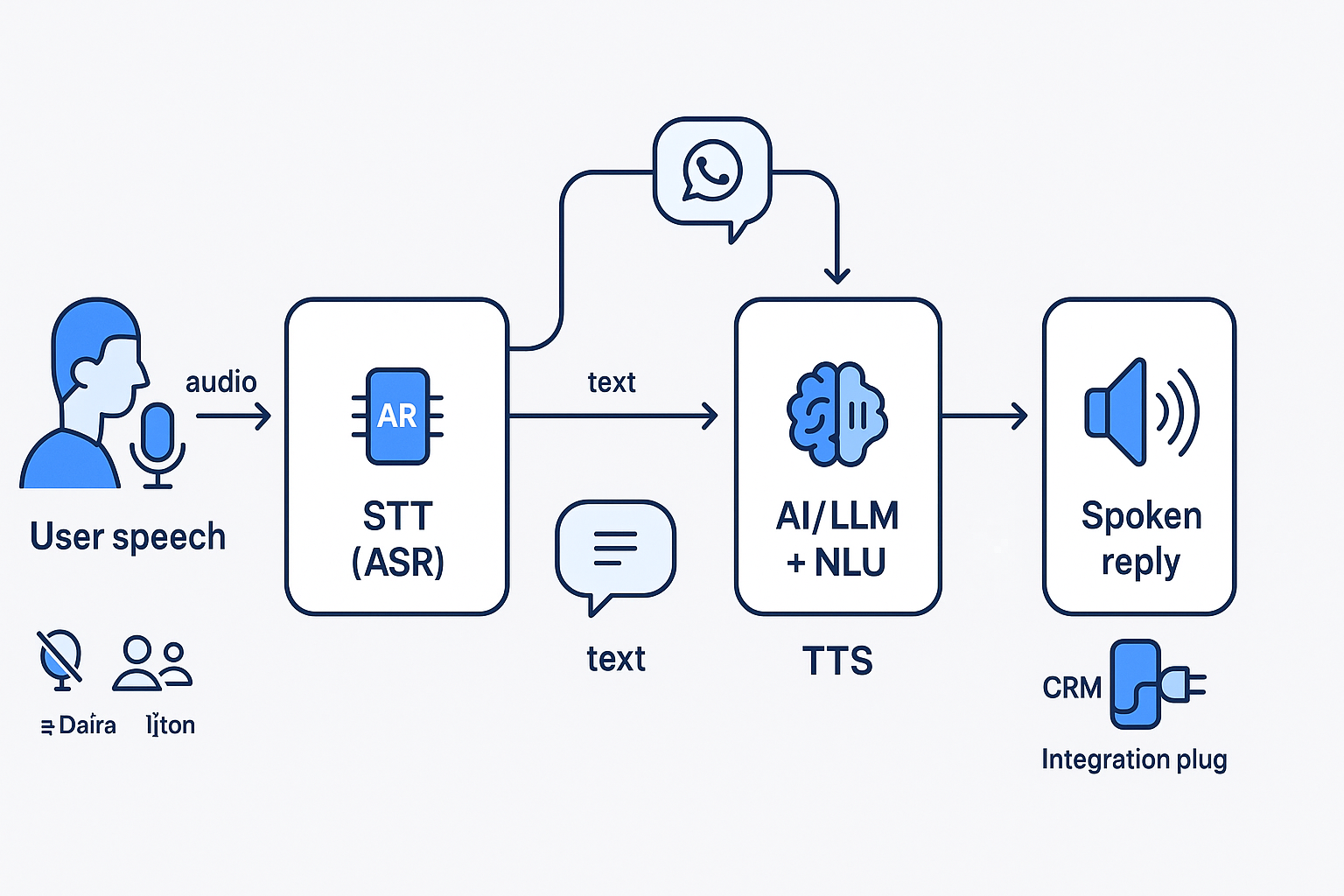
Latency in AI voice agents refers to the total time between when a user stops speaking and when the AI agent begins responding with synthesized speech. This end-to-end measurement encompasses multiple processing stages and represents the most critical performance metric for conversational AI systems.
Key Latency Measurements:
- Total Response Latency: Complete time from speech end to response start
- Processing Latency: Time spent in AI processing (STT + LLM + TTS)
- Network Latency: Communication delays between components
- System Latency: Infrastructure and queue processing overhead
Unlike web applications where users expect some loading time, voice conversations follow natural human speech patterns. Research in cognitive psychology shows that conversational pauses longer than 500ms begin to feel unnatural and can trigger negative user reactions.
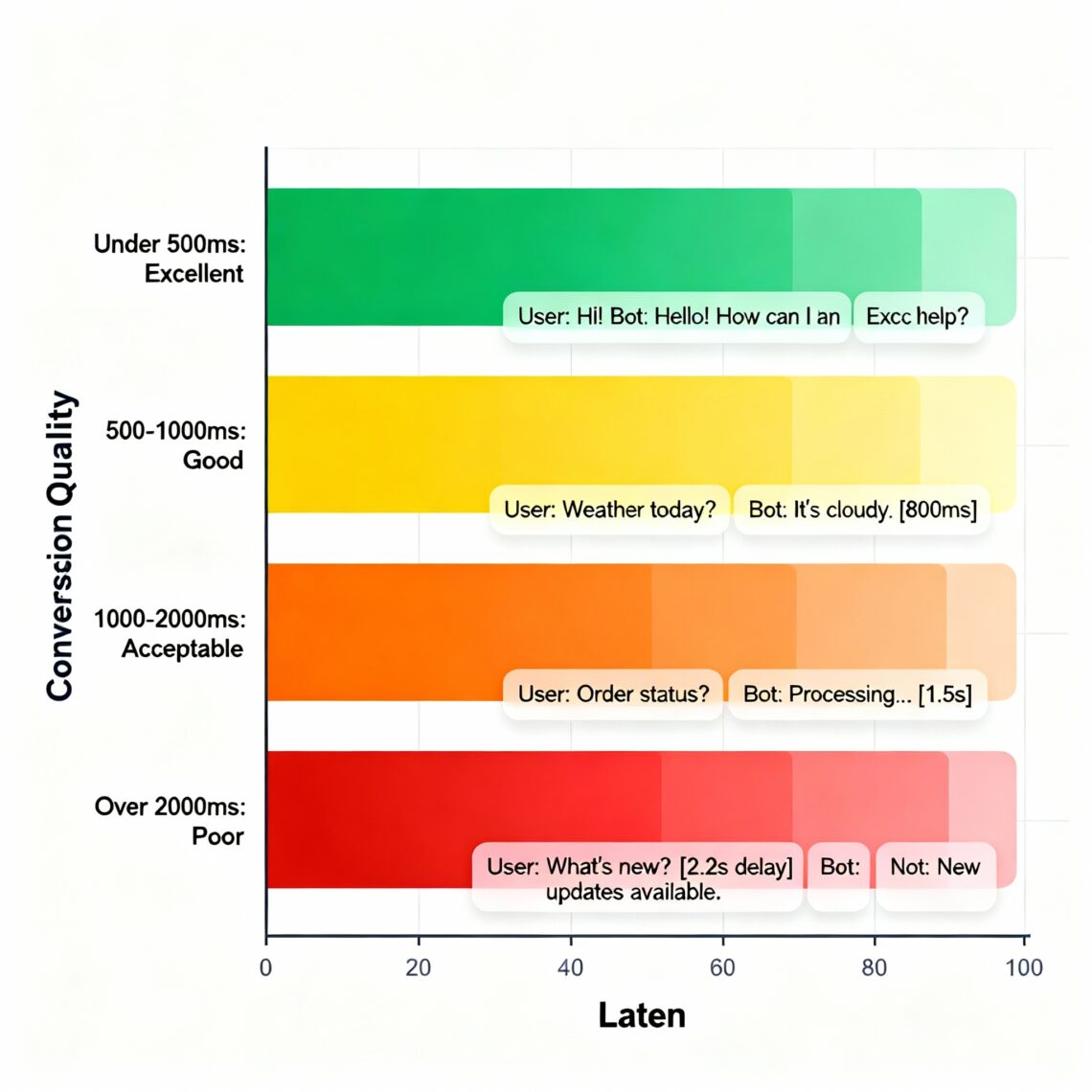
Industry Benchmarks:
- Excellent: Under 500ms total latency
- Good: 500-1000ms total latency
- Acceptable: 1000-2000ms total latency
- Poor: Over 2000ms total latency
The challenge lies in achieving these targets while maintaining high accuracy, natural voice quality, and robust enterprise features.
The Psychology of Conversational Timing

Human conversation follows predictable timing patterns that have evolved over millennia. Understanding these patterns is crucial for designing effective AI voice agents.
Natural Conversation Timing
Human Speech Patterns:
- Turn-taking Gaps: 200-500ms between speakers in natural conversation
- Processing Pauses: Brief hesitations (100-300ms) during complex thinking
- Comfortable Silence: Up to 1 second for thoughtful responses
- Impatience Threshold: Beyond 2 seconds triggers negative reactions
Psychological Impact of Delays:
- Under 200ms: Feels like interruption or overlap
- 200-500ms: Natural, human-like timing
- 500-1000ms: Noticeable but acceptable delay
- 1000-2000ms: Obviously artificial, reduces trust
- Over 2000ms: Frustrating, users may hang up or repeat themselves
User Experience Research
Studies in conversational AI have consistently shown that latency directly impacts:
User Satisfaction Metrics:
- Task Completion Rate: 15% higher with sub-500ms latency
- User Confidence: Faster responses build trust in AI capabilities
- Conversation Length: Users engage longer with responsive agents
- Return Usage: Lower latency strongly correlates with repeat usage
Business Impact:
- Call Abandonment: Increases 25% when latency exceeds 1 second
- Customer Satisfaction: Direct correlation between response speed and CSAT scores
- Brand Perception: Slow responses perceived as outdated or unreliable technology
- Competitive Advantage: Sub-500ms performance differentiates premium solutions
Latency Breakdown: Where Time Goes

Understanding where latency occurs is essential for effective optimization. Modern AI voice agents involve multiple sequential and parallel processing stages, each contributing to the total response time.
Component-by-Component Analysis
1. Speech-to-Text (STT) Processing: 100-300ms
The first bottleneck occurs during speech recognition, where audio is converted to text:
textAudio Buffer → Voice Activity Detection → Speech Recognition → Confidence Scoring → Text Output
Typical Range: 100-300ms
STT Latency Factors:
- Audio Buffering: 50-100ms for sufficient audio context
- Model Complexity: Larger, more accurate models require more processing time
- Language Processing: Multi-language models may have higher latency
- Confidence Scoring: Additional time for accuracy verification
- Network Transmission: API calls to cloud-based STT services
Optimization Opportunities:
- Streaming Recognition: Process audio in real-time chunks
- Local Processing: On-device STT to eliminate network latency
- Optimized Models: Balance accuracy with processing speed
- Voice Activity Detection: Start processing before speech completion
2. Large Language Model (LLM) Processing: 200-800ms
The core intelligence processing represents the largest variable in latency:
textText Input → Context Retrieval → Model Inference → Response Generation → Output Formatting
Typical Range: 200-800ms
LLM Latency Factors:
- Model Size: Larger models (70B+ parameters) require more processing time
- Context Length: Longer conversation history increases processing time
- Generation Length: Longer responses require more token generation time
- Model Architecture: Different architectures have varying processing speeds
- Hardware Acceleration: GPU availability and optimization level
Processing Time by Model Type:
- Fast Models (GPT-3.5): 200-400ms for typical responses
- Balanced Models (GPT-4): 300-600ms for typical responses
- Large Models (Claude-3): 400-800ms for typical responses
- Specialized Models: Variable based on optimization and use case
3. Text-to-Speech (TTS) Synthesis: 150-400ms
Converting the LLM response back to natural-sounding speech:
textResponse Text → SSML Processing → Voice Synthesis → Audio Generation → Stream Output
Typical Range: 150-400ms
TTS Latency Factors:
- Voice Quality: Higher quality voices require more processing
- Synthesis Method: Neural vs concatenative synthesis speeds
- Audio Length: Longer responses increase synthesis time linearly
- Voice Customization: Custom voices may have additional overhead
- Streaming Capability: Ability to start playback during synthesis
4. Network and Infrastructure Latency: 50-200ms
Often overlooked but critically important infrastructure delays:
textComponent Communication → API Calls → Data Transmission → Queue Processing → Response Routing
Typical Range: 50-200ms
Infrastructure Latency Sources:
- Geographic Distance: Physical distance between processing components
- Network Congestion: Internet and carrier network delays
- API Response Time: Third-party service response times
- Load Balancing: Request routing and server selection overhead
- Database Queries: Context retrieval and logging operations
Total Latency Calculation
textTotal Latency = STT + LLM + TTS + Network + Processing Overhead
Example Calculation:
- STT Processing: 180ms
- LLM Generation: 450ms
- TTS Synthesis: 220ms
- Network Latency: 90ms
- System Overhead: 60ms
Total: 1000ms
Target Optimization:
To achieve sub-500ms performance, each component must be optimized:
- STT: Under 150ms
- LLM: Under 250ms
- TTS: Under 150ms
- Network: Under 50ms
- Overhead: Under 50ms
The Sub-500ms Benchmark
The 500ms threshold isn’t arbitrary—it’s based on extensive research in human psychology, conversational AI usability studies, and practical implementation experience from leading voice AI platforms.
Scientific Foundation
Cognitive Research:
- Conversation Analysis: Studies of natural human dialogue patterns
- Response Expectation: Psychological research on conversational timing
- Technology Acceptance: User tolerance for AI response delays
- Task Completion: Impact of latency on successful interactions
Industry Validation:
Leading technology companies have converged on similar benchmarks:
- Google Assistant: Targets under 500ms for voice interactions
- Amazon Alexa: Optimizes for sub-400ms response times
- Apple Siri: Aims for under 600ms end-to-end latency
- Enterprise Platforms: Premium solutions consistently target sub-500ms
Business Impact of Sub-500ms Performance
Customer Experience Metrics:
- 28% Higher Satisfaction: Users rate sub-500ms agents significantly higher
- 40% Longer Engagement: Conversations continue longer with responsive agents
- 35% Better Task Completion: Users successfully complete more requests
- 50% Higher Conversion: Sales and support outcomes improve dramatically
Operational Benefits:
- Reduced Support Costs: Faster resolution leads to shorter calls
- Higher Agent Efficiency: AI handles more interactions per unit time
- Improved Scalability: Better user experience enables higher automation rates
- Competitive Differentiation: Sub-500ms performance distinguishes premium platforms
Technical Challenges
Achieving sub-500ms latency consistently requires addressing multiple technical challenges:
Processing Optimization:
- Parallel Processing: Running STT, context preparation, and response planning simultaneously
- Predictive Processing: Anticipating likely responses during user speech
- Edge Computing: Moving processing closer to users to reduce network latency
- Hardware Acceleration: Leveraging specialized AI chips and GPUs
Architecture Decisions:
- Streaming vs Batch: Real-time streaming vs batch processing trade-offs
- Local vs Cloud: On-device processing vs cloud-based services
- Synchronous vs Asynchronous: Processing pipeline design decisions
- Caching Strategies: Intelligent caching of common responses and contexts
Measuring and Monitoring Latency
Effective latency optimization requires comprehensive measurement and monitoring systems that provide visibility into every aspect of the voice processing pipeline.
Key Performance Indicators (KPIs)
Primary Latency Metrics:
- End-to-End Latency: Total time from speech end to response start
- Component Latency: Individual timing for STT, LLM, and TTS
- Network Latency: Round-trip time for all API calls
- Queue Time: Time spent waiting for processing resources
Statistical Measurements:
- Average Latency: Mean response time across all interactions
- 95th Percentile: Latency experienced by 95% of users
- 99th Percentile: Performance under peak load conditions
- Maximum Latency: Worst-case response times
Quality vs Speed Metrics:
- Accuracy vs Latency: Trade-offs between speed and recognition accuracy
- Natural Speech Quality: Voice synthesis quality at different speeds
- Context Preservation: Maintaining conversation quality under time pressure
- Error Recovery: Handling mistakes without adding latency
Monitoring Infrastructure
Real-Time Dashboards:
textComponent Status:
├── STT Services: 145ms avg, 99% uptime
├── LLM Processing: 320ms avg, 98% uptime
├── TTS Synthesis: 180ms avg, 99.5% uptime
├── Network RTT: 45ms avg, 99.9% uptime
└── Total Latency: 690ms avg, 94% under 1s
Alerting Systems:
- Latency Threshold Alerts: Notifications when latency exceeds targets
- Component Failure Detection: Automatic failover for failed services
- Performance Degradation: Early warning for declining performance
- Capacity Planning: Alerts for resource utilization limits
Analytics and Reporting:
- Historical Trends: Long-term latency performance analysis
- Geographic Variations: Latency differences across regions
- User Segment Analysis: Performance variations by user type
- Correlation Analysis: Relationship between latency and user satisfaction
Testing and Optimization
Load Testing:
- Concurrent User Simulation: Testing performance under realistic load
- Peak Traffic Scenarios: Ensuring performance during high usage
- Stress Testing: Understanding system breaking points
- Geographic Testing: Performance validation across different regions
A/B Testing Framework:
- Latency Impact Studies: Measuring user behavior changes with different latency levels
- Component Optimization: Testing different STT, LLM, and TTS configurations
- Architecture Variations: Comparing different processing pipeline designs
- User Experience Research: Qualitative feedback on latency impact
Optimization Strategies and Techniques

Achieving consistent sub-500ms latency requires a systematic approach to optimization across all components of the voice AI system.
STT Optimization Strategies
1. Streaming Speech Recognition
textTraditional: [Audio Buffer] → [Complete STT] → [Output]
Streaming: [Audio Chunk] → [Partial STT] → [Continuous Output]
Latency Reduction: 50-150ms
Implementation Techniques:
- Voice Activity Detection (VAD): Start processing before speech completion
- Partial Transcription: Generate interim results during speech
- Context Prediction: Anticipate likely speech patterns
- Buffer Optimization: Minimize audio buffering requirements
2. Model Selection and Optimization
- Lightweight Models: Use faster models for time-critical applications
- Custom Vocabulary: Optimize for domain-specific terminology
- Language-Specific Models: Avoid multi-language overhead when possible
- Hardware Acceleration: Leverage GPU and specialized AI chips
3. Local Processing Implementation
- Edge STT: On-device speech recognition to eliminate network latency
- Hybrid Approach: Local processing with cloud fallback
- Progressive Enhancement: Start with fast local processing, refine with cloud
- Bandwidth Optimization: Efficient audio compression and transmission
LLM Optimization Strategies
1. Model Architecture Optimization
textProcessing Pipeline:
├── Intent Classification: 50ms (lightweight model)
├── Context Preparation: 80ms (parallel processing)
├── Response Generation: 200ms (optimized LLM)
├── Post-Processing: 40ms (formatting and safety)
└── Total LLM Time: 370ms
Model Selection Criteria:
- Latency vs Quality Trade-offs: Choose optimal model size for use case
- Specialized Models: Use task-specific models for common scenarios
- Model Distillation: Create faster models from larger, more accurate ones
- Dynamic Model Selection: Route different query types to optimal models
2. Context and Memory Optimization
- Intelligent Context Pruning: Keep only relevant conversation history
- Hierarchical Context: Store context at different granularity levels
- Compression Techniques: Efficient encoding of conversation state
- Predictive Context Loading: Preload likely context during user speech
3. Response Generation Acceleration
- Template-Based Responses: Pre-generated responses for common scenarios
- Streaming Generation: Start TTS processing during LLM generation
- Parallel Processing: Generate multiple response options simultaneously
- Response Caching: Cache common responses with context awareness
TTS Optimization Strategies
1. Streaming Speech Synthesis
textTraditional: [Complete Text] → [Full Audio Generation] → [Playback]
Streaming: [Text Chunks] → [Progressive Audio] → [Immediate Playback]
Latency Reduction: 100-200ms
Implementation Benefits:
- Immediate Playback: Start audio while continuing synthesis
- Perceived Latency: Users hear response faster even if total time is similar
- Error Recovery: Handle synthesis errors without complete restart
- Bandwidth Efficiency: Stream audio as it’s generated
2. Voice Model Optimization
- Pre-loaded Voices: Keep common voices in memory
- Optimized Models: Use faster synthesis models for time-critical applications
- Quality vs Speed: Balance voice naturalness with generation speed
- Custom Voice Acceleration: Optimize custom voices for performance
3. Audio Processing Optimization
- Format Optimization: Use efficient audio codecs for transmission
- Compression Techniques: Balance quality with file size/transmission time
- Hardware Acceleration: Leverage audio processing hardware
- Parallel Synthesis: Generate audio segments in parallel
Infrastructure and Network Optimization
1. Edge Computing Implementation
textTraditional Cloud Architecture:
User → Internet → Cloud Processing → Response
Total Network Latency: 100-300ms
Edge Computing Architecture:
User → Edge Node → Local Processing → Response
Total Network Latency: 20-50ms
Edge Deployment Benefits:
- Reduced Network Latency: Processing closer to users
- Better Performance: Consistent latency regardless of location
- Improved Privacy: Sensitive data stays local
- Offline Capability: Basic functionality without internet
2. CDN and Caching Strategies
- Geographic Distribution: Cache resources close to users
- Intelligent Caching: Cache based on usage patterns and geography
- API Response Caching: Cache common API responses
- Asset Optimization: Optimize voice models and other assets
3. Network Protocol Optimization
- HTTP/2 and HTTP/3: Use modern protocols for better performance
- Connection Pooling: Reuse connections to reduce overhead
- Compression: Optimize data transmission sizes
- Protocol Selection: Choose optimal protocols for different data types
System Architecture Optimization
1. Microservices Architecture
textParallel Processing Pipeline:
├── STT Service (150ms)
├── Context Service (80ms, parallel with STT)
├── LLM Service (250ms)
├── TTS Service (120ms, starts during LLM)
└── Total Optimized: 420ms (vs 600ms sequential)
2. Asynchronous Processing
- Non-blocking Operations: Prevent waiting for unrelated operations
- Event-Driven Architecture: React to events rather than polling
- Queue Management: Efficient message passing between components
- Resource Pooling: Reuse expensive resources across requests
3. Load Balancing and Scaling
- Intelligent Routing: Route requests to optimal servers
- Auto-scaling: Automatically adjust capacity based on demand
- Resource Allocation: Distribute computing resources efficiently
- Health Monitoring: Detect and route around unhealthy services
Real-World Performance Analysis
Understanding how latency performs in real-world scenarios helps set realistic expectations and identify optimization priorities.
Performance by Use Case
Customer Service Applications:
textTypical Latency Profile:
├── Simple FAQ: 300-500ms (template responses)
├── Account Lookup: 600-900ms (database queries)
├── Complex Problem-Solving: 800-1200ms (multi-step reasoning)
└── Escalation Handoff: 200-400ms (simple routing)
Sales and Lead Qualification:
textTypical Latency Profile:
├── Initial Greeting: 250-400ms (fast engagement critical)
├── Information Collection: 400-700ms (form filling)
├── Product Recommendations: 600-1000ms (complex logic)
└── Appointment Scheduling: 500-800ms (calendar integration)
Healthcare Applications:
textTypical Latency Profile:
├── Symptom Assessment: 500-800ms (accuracy critical)
├── Appointment Booking: 400-600ms (calendar integration)
├── Medication Reminders: 200-400ms (simple confirmations)
└── Emergency Screening: 300-500ms (fast triage important)
Geographic Performance Variations
Network Infrastructure Impact:
- Major US Cities: 250-500ms typical latency
- European Markets: 300-600ms typical latency
- Asia-Pacific: 400-800ms typical latency
- Emerging Markets: 600-1200ms typical latency
Optimization Strategies by Region:
- Developed Markets: Focus on sub-500ms performance
- Emerging Markets: Balance latency with cost and reliability
- Rural Areas: Implement edge computing and caching
- Mobile Networks: Optimize for variable network conditions
Industry Benchmarks
Enterprise Voice AI Platforms:
- Premium Platforms: 300-600ms average latency
- Mid-Market Solutions: 500-1000ms average latency
- Budget Platforms: 800-1500ms average latency
- Custom Solutions: Highly variable (200-2000ms)
Comparison with Traditional Systems:
- Human Agents: 500-2000ms natural response time
- IVR Systems: 200-500ms menu navigation
- Chatbots: 100-300ms text response time
- Voice Assistants: 300-800ms consumer device performance
Enterprise Latency Considerations
Enterprise deployments introduce additional complexity that can impact latency performance and optimization strategies.
Security and Compliance Impact
Encryption Overhead:
- TLS Processing: 20-50ms additional latency per connection
- End-to-End Encryption: Additional processing for sensitive data
- Certificate Validation: SSL/TLS handshake overhead
- Data Sanitization: Processing time for compliance requirements
Audit and Logging:
- Real-Time Logging: Database writes can add 10-30ms
- Compliance Monitoring: Additional processing for regulatory requirements
- Audit Trails: Comprehensive logging without impacting performance
- Data Retention: Efficient storage of conversation data
Integration Complexity
CRM Integration Latency:
textCustomer Data Retrieval:
├── Database Query: 50-200ms
├── API Call Processing: 30-100ms
├── Data Transformation: 20-50ms
├── Context Preparation: 40-80ms
└── Total Integration: 140-430ms
Multi-System Integration:
- Authentication Systems: SSO and user verification overhead
- Business Logic: Custom workflow processing time
- Data Synchronization: Real-time updates across systems
- Error Handling: Robust error recovery without latency impact
Scale and Performance
Concurrent User Handling:
- Resource Contention: Managing processing resources under load
- Queue Management: Balancing throughput with latency
- Auto-Scaling: Dynamic resource allocation for peak loads
- Performance Isolation: Preventing one customer from impacting others
Enterprise SLA Requirements:
- 99.9% Uptime: High availability with consistent performance
- Latency Guarantees: Contractual commitments to response times
- Regional Performance: Consistent latency across global deployments
- Peak Load Handling: Maintaining performance during high usage
Technology Trade-offs and Decisions
Achieving optimal latency requires making informed trade-offs between various technical and business considerations.
Accuracy vs Speed Trade-offs
Speech Recognition:
textModel Comparison:
├── Fast Model: 100ms, 92% accuracy
├── Balanced Model: 180ms, 96% accuracy
├── Accurate Model: 280ms, 98% accuracy
└── Premium Model: 450ms, 99% accuracy
Decision Framework:
- Error Cost: Impact of recognition mistakes on user experience
- Use Case Tolerance: Different applications have different accuracy requirements
- Recovery Mechanisms: Ability to correct errors without starting over
- User Expectations: Balance between speed and reliability
Language Model Selection:
- Simple Queries: Use faster, smaller models for basic interactions
- Complex Reasoning: Accept higher latency for better accuracy
- Hybrid Approach: Route different query types to optimal models
- Fallback Strategies: Graceful degradation when fast models are insufficient
Cost vs Performance Optimization
Infrastructure Costs:
- Edge Computing: Higher infrastructure costs for lower latency
- Premium Models: More expensive AI services for better performance
- Redundancy: Additional costs for high availability and performance
- Geographic Distribution: Multiple regions increase costs but improve performance
Operational Trade-offs:
- Model Training: Investment in custom models vs using generic solutions
- Monitoring Systems: Comprehensive monitoring increases overhead but enables optimization
- Technical Talent: Specialized expertise required for advanced optimization
- Maintenance Complexity: More optimized systems require more sophisticated maintenance
Scalability Considerations
Processing Architecture:
textScaling Strategy Comparison:
├── Vertical Scaling: Faster but limited scalability
├── Horizontal Scaling: Better scalability, more complex latency management
├── Auto-Scaling: Dynamic but can introduce latency variability
└── Hybrid Approach: Optimal but most complex to implement
Resource Management:
- Predictive Scaling: Anticipate demand to pre-scale resources
- Resource Pooling: Share expensive resources across multiple users
- Priority Queuing: Handle urgent requests faster
- Load Distribution: Balance load while maintaining low latency
Future of Ultra-Low Latency Voice AI
The evolution of AI voice agent technology continues to push the boundaries of what’s possible in terms of response speed and natural conversation flow.
Emerging Technologies
Next-Generation AI Chips:
- Specialized Voice Processors: Hardware optimized specifically for voice AI workloads
- Neural Processing Units (NPUs): Dedicated AI processing with ultra-low latency
- Edge AI Chips: Powerful AI processing in mobile and IoT devices
- Quantum-Classical Hybrid: Quantum acceleration for specific AI tasks
Advanced Model Architectures:
- Mixture of Experts: Dynamic model selection for optimal speed-accuracy balance
- Streaming Transformers: Real-time processing of streaming audio and text
- Compressed Models: Maintaining quality while dramatically reducing size
- Predictive Processing: Models that anticipate user needs and pre-generate responses
Breakthrough Targets
Ultra-Low Latency Goals:
- Sub-200ms Total Latency: Approaching human reaction time
- Sub-100ms Component Latency: Each component optimized to theoretical limits
- Real-Time Streaming: Truly simultaneous processing and response
- Predictive Responses: Generating responses before users finish speaking
Technical Enablers:
- 5G and 6G Networks: Ultra-low latency network infrastructure
- Edge Computing Evolution: More powerful processing at the network edge
- AI Hardware Acceleration: Specialized chips for different AI workloads
- Advanced Caching: Intelligent prediction and pre-computation of responses
Impact on User Experience
Conversational Naturalness:
- Interruption Handling: Natural conversation with overlapping speech
- Real-Time Feedback: Immediate acknowledgment of user input
- Contextual Responses: Instant access to relevant information and history
- Emotional Responsiveness: Real-time adaptation to user emotional state
Business Applications:
- Crisis Management: Instant response capability for emergency situations
- High-Frequency Trading: Voice interfaces for time-critical financial decisions
- Real-Time Translation: Simultaneous interpretation with minimal delay
- Live Event Support: Instant customer service during high-demand events
Conclusion
Latency is the invisible foundation that makes or breaks AI voice agent experiences. The difference between 300ms and 800ms response time determines whether users perceive your AI as intelligent and helpful or slow and robotic.
Key Takeaways:
- Sub-500ms is Critical: This threshold represents the boundary between natural and artificial conversation experiences.
- Every Component Matters: STT, LLM, TTS, and network latency must all be optimized for consistent performance.
- Real-World Complexity: Enterprise deployments introduce additional latency considerations around security, integration, and scale.
- Continuous Optimization: Achieving and maintaining low latency requires ongoing monitoring, testing, and optimization.
- Strategic Trade-offs: Balancing latency with accuracy, cost, and functionality requires careful architectural decisions.
The Business Impact:
Organizations that prioritize latency optimization in their AI voice agents will see:
- Higher customer satisfaction and engagement
- Better task completion rates and user success
- Competitive differentiation in the market
- Increased automation success and ROI
As AI voice technology continues to evolve, the platforms and organizations that master latency optimization will lead the market. The sub-500ms benchmark isn’t just a technical target—it’s a competitive necessity for delivering truly exceptional conversational AI experiences.
TringTring.AI’s Approach:
At TringTring.AI, we’ve architected our omnichannel platform specifically for sub-500ms performance:
- Streaming processing at every stage of the pipeline
- Edge computing deployment options for global low latency
- Intelligent caching and predictive processing
- Real-time monitoring and optimization
- Enterprise-grade infrastructure with latency guarantees
The future of conversational AI belongs to platforms that can deliver human-like response times while maintaining the intelligence and capabilities that make AI agents valuable. Understanding and optimizing latency isn’t just a technical requirement—it’s the foundation of exceptional customer experiences.
Ready to experience sub-500ms AI voice agents? Test TringTring.AI’s live demos and see the difference low latency makes in conversational AI.
Related Reading:
- How AI Voice Agents Work: A Complete Technical Guide
- Real-Time Voice AI: The Architecture Behind Human-Like Conversations
- Voice AI Security: Protecting Conversations in Enterprise Deployments
- Building Scalable Voice AI: From MVP to Enterprise
This technical analysis is part of TringTring.AI’s educational content series on conversational AI optimization. For more insights on voice AI performance, enterprise deployment, and technical best practices, explore our complete blog collection.